🏗️ AerynOS: The OS As Infrastructure
Taking a break from our usual release-oriented updates, I thought it was high time to dive into what AerynOS actually is and what sets it apart from other distros. Fair warning, this is a meaty, in depth post, and still only scratches the surface. If you’re interested in the future of Linux distributions, read on. It may also help to visit our work-in-progress documentation site for more information.
🧱 The OS As Infrastructure
Section titled “🧱 The OS As Infrastructure”Firstly, AerynOS isn’t Yet Another Linux Distribution. It’s a platform, a foundation, and a set of tools engineered in accordance with a vision and design that just so happens to produce a Linux distribution. Were we to go back in time and build a design brief for AerynOS, the initial question might be:
What if the operating system itself behaved like modern infrastructure?
AerynOS is the answer to that question. What if, instead of doing things the way they’ve always been done, we started from the ground up and produced a well designed system, rather than the traditional model of in-place mutation internal to a distribution?
🏗️ The AerynOS Foundation
Section titled “🏗️ The AerynOS Foundation”Leveraging years of experience across the industry, including some notable pioneering projects such as Solus, Clear Linux, and others, we set out to build things the hard way, in order to make them easy.. eventually.
🔧 Toolchain
Section titled “🔧 Toolchain”At the very core, is the decision to not be another GNU/Linux distribution. We default to the LLVM toolchain, using libc++
and compiler-rt by default. This isn’t just a case of “we like LLVM”, but rather a strategic decision to leverage the
superior diagnostics, and ensure correctness / portability of packages. Whilst in our very early stages a few years ago
we did trial musl, we do default to glibc for compatibility reasons and its superior performance characteristics.
The performance advantage of glibc over musl is well-documented, particularly for compute-intensive workloads and applications
requiring optimal threading performance. We’re here to build a working, usable system, for a multitude of use cases and verticals,
and glibc provides the best balance of compatibility and performance.
Note, we do still package gcc and it’s trivial to enforce its use in a package recipe by setting the toolchain field
in stone.yaml to gnu.
Lastly, it’s worth noting we build all packages for x86_64-v2 as our minimum baseline, and perform targeted optimisation
in our package recipes using the extensive tuning options configurable in boulder.
📄 Statelessness
Section titled “📄 Statelessness”Our packages are forbidden from containing any files outside of /usr. In order to enable this, packages and/or configurations
are altered in AerynOS to ensure they can operate in the absence of a user provided configuration. This forces us to ensure
sane-defaults are baked in at all levels, and eliminates dreaded 3-way merge conflicts on package updates. There are no conflicts,
because everything in /etc and /var is yours. Likewise, /usr belongs exclusively to the system.
This approach was coined and developed during Clear Linux and Solus days, and we’re refining it further in AerynOS. Other projects
have adopted similar approaches, termed “hermetic /usr”.
You might be wondering how files end up in /etc automatically. To this end, we support two forms of package triggers:
🔄 Transaction Triggers
Section titled “🔄 Transaction Triggers”These triggers are run at the end of a transaction in an ephemeral container (linux namespace) and may affect the contents of the
transaction-specific /usr tree. This is useful for interdependent packages that need to dynamically produce plugin registries, for
example.
🖥️ System Triggers
Section titled “🖥️ System Triggers”These triggers do not run in an isolated container, but instead are run in the context of the host system after the transaction
has been successfully built and applied. It is these (minimally used) triggers that invoke systemd-tmpfiles, systemd-sysusers, etc.
Even for these cases we take special care to ensure that our default configs are sane and that a rebuild is always possible.
👤 System Accounts
Section titled “👤 System Accounts”Another important aspect is the handling of local system accounts. Traditionally these are snippets/shell scripts that invoke useradd,
groupadd, etc. In AerynOS we default to systemd userdb for any users/groups that do not explicitly need groups that users would
join. Thus, using drop-ins in /usr/lib/userdb, most accounts are defined and made available via NSS. We use this already in
gdm, polkit, colord, and many others.
For the other cases, we utilise systemd-sysusers using snippets in /usr/lib/sysusers.d to create the necessary system accounts.
In time, when GNOME and other desktops (as well as shadow et al.) are more adapted to userdb and systemd-homed, we won’t need to rely
so much on sysusers. The goal of course is elimination of /etc/passwd and /etc/group entirely, facilitating quicker recovery,
provisioning, etc. For now some packages will ship sysusers-based groups, ie docker group, etc.
⚛️ Atomic Updates
Section titled “⚛️ Atomic Updates”Every moss transaction is atomic. Very high level: we produce a new usr tree (rootfs essentially due to mandated usr-merge) very quickly
using hardlinks from a deduplicated cache. Once successfully built and primed, we atomically swap the new tree into place. Effectively, the
staged transaction is swapped with the real /usr using renameat2 with RENAME_EXCHANGE. It either works or it doesn’t. Nothing in between.
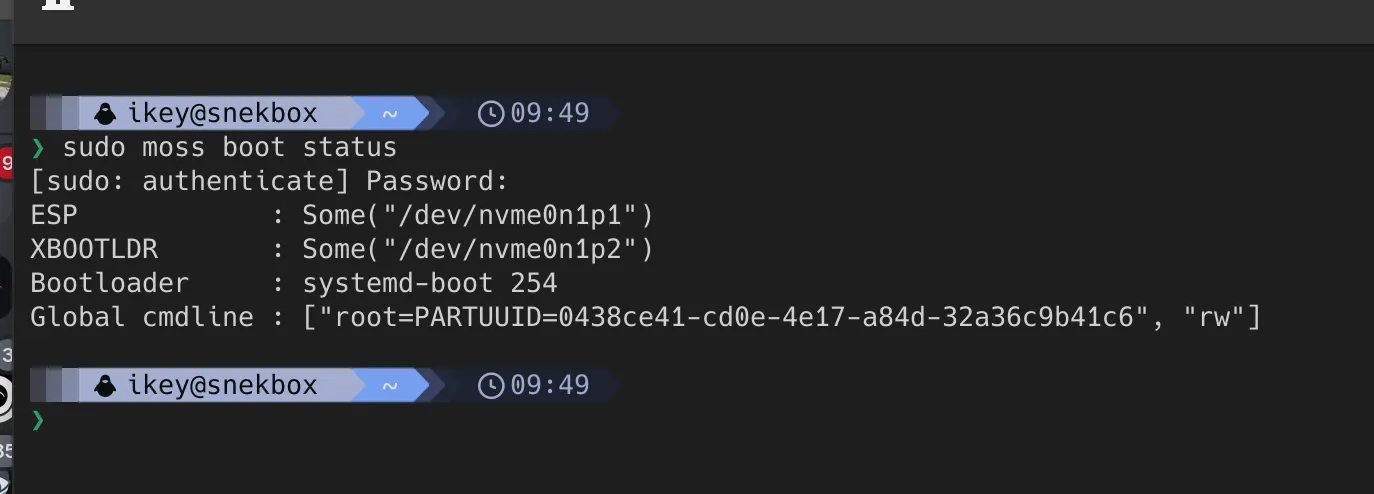
🥾 Boot Management
Section titled “🥾 Boot Management”Leaning heavily on our blsforme and disks-rs projects, we’ve taken
a very different approach to boot management. As part of applying a transaction, we produce a Boot Loader Specification (BLS) entry for the new
transaction. The tooling will discover the EFI System Partition (ESP), and mount it if necessary. It then synchronises the bootloader itself (systemd-boot),
the relevant BLS entries, and the kernel/initramfs. Additionally it will automatically garbage collect older entries, currently retaining 5 of the last
transactions.
It’s not just a case of copy/paste and hope for the best. We dynamically produce the root parameters for the kernel command line by directly reading the
superblocks (natively, in Rust) of the devices all the way up the chain for the root filesystem. It means there’s no configuration file anywhere in AerynOS
containing your root= parameter, and we’re even able to read LUKS2 encrypted devices to add the rd.luks.uuid parameter.
If that wasn’t cool enough, we also encode the moss transaction ID into the kernel command line. This is picked up during early boot
in our initramfs, before /sysroot is pivoted to. Long story short it means that every kernel is correctly synchronised with the right rootfs,
and that rollback is cheap, easy, and accessible directly from the boot menu.
In addition, we also automatically support XBOOTLDR partitions. In the absence of LoaderDevicePartUUID EFI variable, we’ll scan the
GPT table itself relative to the rootfs to find the ESP, and we’ll always scan GPT relative to ESP to find the XBOOTLDR partition.
Long story short? No /etc/default/grub. In fact, if you wipe your ESP, moss can rebuild it from scratch.
📦 The Stone Format
Section titled “📦 The Stone Format”At the heart of moss lies our .stone format. At a basic level, it’s our binary package format. Using a version-agnostic header, we’ve ensured
that we design for the future. We also version every payload within the stone, allowing us to refine and evolve the format over time. Currently we support
4 payloads in a single stone:
- 📄 Content payload: A sequential blob of deduplicated data
- 🔍 Index payload: Contains offsets for the content payload, keyed by the XXH128 hash of the content
- 🗂️ Layout payload: Describes the intended filesystem layout when the stone is applied
- 📋 Metadata payload: Sequence of strongly typed, tagged metadata entries such as name, providers, etc.
Right now we default to XXH128 for hashing, but Blake3 is on the horizon (and used in blsforme). We compress all payloads using Zstd, offering great decompression performance whilst still providing a decent compression ratio.
The process for “installing” a .stone is quite different to other systems.
- 📥 The stone is fetched according to the repository data
- 🧠 Index payload is unpacked in memory
- 🗜️ Content payload is decompressed in a single run to a temporary location
- 🔗 Using the index payload, the content payload is spliced into the content addressable storage (CAS)
- 📂 The layout payload is loaded and merged into the LayoutDB, keyed by the unique package ID (SHA256 for the entire
.stone, per the repo) - 📊 Using the same key, the metadata payload is loaded into the “InstallDB”.
Notice that at no point are we actually “installing” anything. We cache into the CAS, and store metadata and layout details. This is used when producing a transaction. Also note there are various safe guards, integrity checks and such in place. For example every payload contains a “CRC” in the payload header, verified on read. We actually use XXH64 for this.
🔁 What is a transaction?
Section titled “🔁 What is a transaction?”In AerynOS, a transaction is an entirely self-contained rootfs produced by moss. Right now we have to emulate imperative package management,
by producing a new dependency graph seeded from the previous system state as recorded in the StateDB. Alterations are made and validated, and then
the new DAG selects the packages to be included in the transaction.
At a high level, the transaction is produced by:
- 📊 Producing a valid dependency graph, seeded from the previous system state
- 🧮 Determine cache availability for each package
- 📥 Fetch and cache every missing
.stoneto produce the transaction - 📂 Load all layouts for the stones by ID
- 🌐 Using our multi-layered vfs approach, we build an arena graph of the target filesystem, detecting conflicts ahead of time, whilst also precomputing reparented nodes (i.e symlink redirection) and produce an optimal iteration order for transaction application
- 🚶 Walking the vfs iterator to produce the new rootfs in a staging location, using
linkat,mkdirat, etc, to optimally produce the new filesystem, linked from the deduplicated cache - 📦 Binding an ephemeral container to the new rootfs, and running transaction triggers
- 💾 Recording the transaction in the StateDB.
As mentioned above, once a successful transaction is produced, it is atomically swapped into place. If the transaction fails, no ill effects are observed on the system, and your work day continues as normal. In the event of a successful transaction, the system is updated and ready to go, along with system trigger execution and boot management updates.
🔮 The Future
Section titled “🔮 The Future”All of this is just the start. It’s taken a few years, and perhaps now it’s clear why. We’ve not even covered our package build tool, boulder,
or indeed our build infrastructure! With that said, lets skip forward a short while and see what’s coming down the pipe.
🌍 Beyond the distro model
Section titled “🌍 Beyond the distro model”To reiterate, we emulate imperative package management. And to be honest, it’s totally pointless. It actually introduces more bugs than it solves. Given that we produce a new rootfs for every transaction, we could just as easily produce an entirely new graph each time too.
That’s exactly what we’re planning to do. In a similar vein to Gentoo or Nix, the intent is a global file to explicitly state
the desired state of the system, whilst the tooling will simply fulfil it based on the moss plugin cascade. Whilst we have
no intention of conflating state and configuration, we will in time extend this system model to support variants of packages
in order to provide a kind of “slots” system, and to implement a richer, saner alternative to the infamous update-alternatives.
Obvious candidates include mutually exclusive packages like coreutils and uutils-coreutils (a gnu variant weight, perhaps?) or
coinstallables such as clang, ensuring a default vendor version whilst allowing overrides at the local install or indeed package recipe
level.
🔒 Immutability
Section titled “🔒 Immutability”Often AerynOS is described as an immutable OS, and that’s not strictly true. Granted, every transaction results in a new /usr tree,
so local changes won’t persist and recovery is immediately available. However, we’re not immutable in the sense of read-only.
Having produced a composition-first, developer&user friendly atomic update implementation, we want to take this further in order to also
support immutability without compromise: no unnecessary reboots. To do so we’ll implement something similar to composefs,
without the drawbacks. Using the same transaction driven approach we have now, we’ll simply produce an erofs metadata image dynamically instead
of the exploded filesystem tree. Utilising trusted.overlay.redirect xattr, and an overlayfs mount, we’ll expose our own CAS through the
layouts in erofs, and also support fsverity hashes. Icing on the cake? We’ll leverage mount stacks to retain our composition-first, no
unnecessary reboot ethos.
📚 Versioned repositories
Section titled “📚 Versioned repositories”We’ve touched on this a few times in our blog posts. Essentially the binary repository will be produced as a result of available build artefacts correlating to the state of our git repo manifest files (boulder proofs of build). The main repository index will link releases to moss/stone format versions, such that moss would only update to the latest release that it supports. This allows us to stagger breaking changes in a way that nothing breaks at all.
📊 Current Status
Section titled “📊 Current Status”- 🚀 Actively shipping GNOME ISOs
- 🎮 Quite usable for gaming with NVIDIA drivers, Steam, Flatpak, etc
- 👥 Real users are already praising stability and innovation
- 🛠️ Focused heavily on
disks-rsandlichen-installerto leverage disk strategy files (automatic provisioning described in KDL)
🎉 Conclusion
Section titled “🎉 Conclusion”This isn’t just another distro. It’s us redefining distributing Linux. We’ve achieved a tremendous amount, having successfully integrated all of the above into a cohesive, singular whole. The amusing part of course being that the resulting system is “boring” - it just works.
Now, we are alpha. We’re not done, we’re not without issues. That said, we’re building the future and with your support, we’ll get there even faster. This post has only scratched the surface of AerynOS, but if you like what we’re doing, please do get involved or support us.
Or see other ways in which you can support the project financially.