RELR Brings Smaller Files, More Performance?
RELR is an efficient method of storing relative relocations (but is not yet available in glibc upstream). This has a
significant reduction on file size often in the vicinity of 5% for libraries and even higher for PIE binaries. We also
take a look at the performance impact on enabling RELR and that looks really good too! Smaller files with more
performance - you can have your cake and eat it too!
Delicious Size Savings
Section titled “Delicious Size Savings”Everyone enjoys smaller files, especially when it’s for free! RELR provides a very efficient method of storing
relative relocations where it only requires a few percent compared to storing them in the .rela.dyn section which is
what currently happens. However, it can’t store everything so the .rela.dyn section remains (though much smaller).
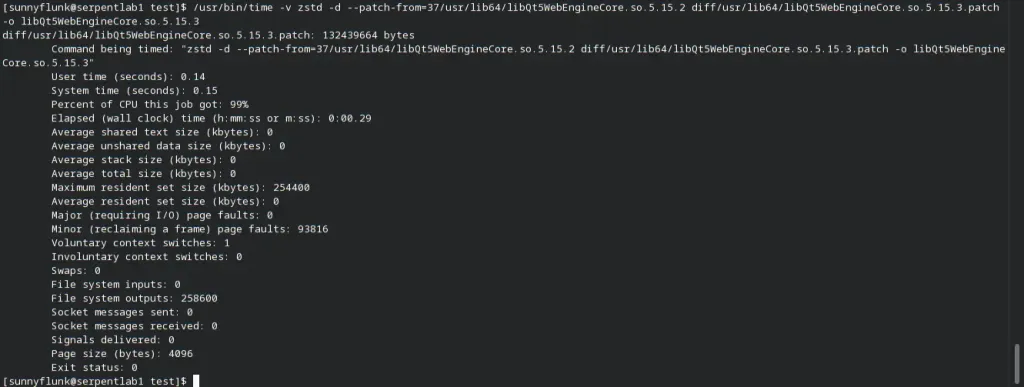
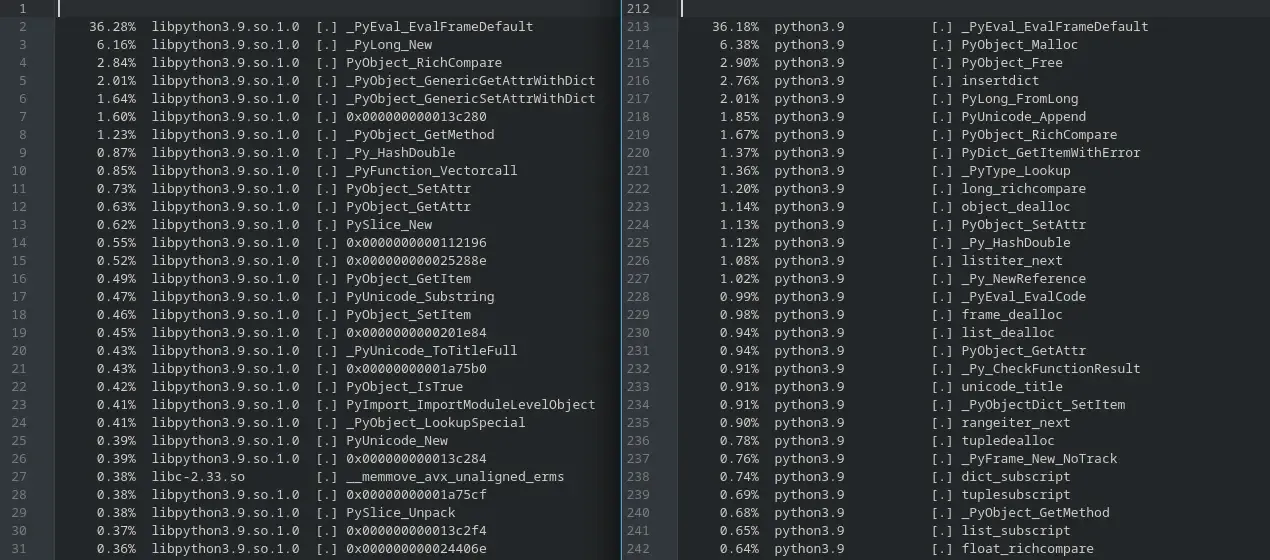
Here’s an example of the sections of libLLVM-13.so with and without RELR. Here we see the .rela.dyn section taking
up a whole 2MB! When enabling RELR, .rela.dyn shrinks down to just under 100KB while adding a new section
.relr.dyn which is just over 20KB! That’s nearly a 1.9MB file size reduction, so you’ll get smaller packages, smaller
updates and it will be even faster to create delta packages from our servers. For reference, some of the biggest files
have a .rela.dyn section over 10MB!
| Section | Without RELR | With RELR |
|---|---|---|
| .dynstr | 2,285,738 | 2,285,723 |
| .rela.dyn | 2,006,472 | 97,464 |
| .relr.dyn | - | 21,688 |
| .text | 28,708,290 | 28,708,386 |
| .dynamic | 592 | 608 |
| Total | 44,853,987 | 42,966,764 |
Smaller, But at What Cost?
Section titled “Smaller, But at What Cost?”While most of the discussion about RELR is around the size savings, there’s been very little in terms of the
performance numbers of enabling RELR. For most things, it’s not going to make a noticeable difference, as it should
only really impact loading of binaries. There’s one rule we have and that’s to measure everything! We care about every
little detail where many 1-2% improvements can add up to significant gains.
First, we require a test to determine if we could detect changes between an LLVM built with RELR and one without.
The speed of the compiler is vital to a distro, where lackluster performance of the build system hurts all contributors
and anyone performing source based builds. clang in this example was built using a shared libLLVM so that it would
load the RELR section and it’s large enough to be able to measure a difference in load times (if one exists). Building
gettext was the chosen test (total time includes tarball extraction, configure, make and make install stages), rather
than a synthetic binary loading test to reflect real world usage. The configure stage is very long when building
gettext so clang is called many times for short compiles. Lets take a look at the results:
no RELR:[Build] Finished: 1 minute, 57 secs, 80 ms, 741 μs, and 2 hnsecs[Build] Finished: 1 minute, 57 secs, 691 ms, 586 μs, and 4 hnsecs[Build] Finished: 1 minute, 56 secs, 861 ms, 31 μs, and 8 hnsecs
RELR:[Build] Finished: 1 minute, 55 secs, 244 ms, 213 μs, and 8 hnsecs[Build] Finished: 1 minute, 55 secs, 400 ms, 158 μs, and 8 hnsecs[Build] Finished: 1 minute, 55 secs, 775 ms, 40 μs, and 8 hnsecs
RELR+startup patch:[Build] Finished: 1 minute, 54 secs, 979 ms, 166 μs, and 8 hnsecs[Build] Finished: 1 minute, 54 secs, 820 ms, and 675 μs[Build] Finished: 1 minute, 54 secs, 713 ms, 440 μs, and 3 hnsecsHere we see the base configuration was able to build gettext in 117.21s on average. When we enabled RELR in our
LLVM build (all other packages were without RELR still), the average build time decreased by 1.74s! That does not
sound like a lot, but the time spent loading clang would only be a portion of the total, yet still gives a 1-2%
performance lift over the whole build. While we were reducing start up time, I ran another test, but this time adding a
patch to reduce paths searched on startup as well as enabling RELR. This patch reduced the average build time by a
further 0.63s!
That’s a 2.37s reduction in the build just from improving the clang binary’s load time.
What This Means - RELR by Default
Section titled “What This Means - RELR by Default”So what actually is RELR? I can’t really do the topic justice, so will point you to a great blog post about RELR,
Relative Relocations and RELR. It’s quite technical
for the average reader, but definitely worth a read if you like getting into the details. To no surprise the author
(Fangrui Song) started the initial push for getting RELR support upstream in glibc (at the time of this post the
patch series has not yet been committed to glibc git).
What I can tell you, is that we’ve applied the requisite patches for RELR support and enabled RELR by default in
boulder for builds. Our container has been rebuilt and all is working well with RELR enabled. More measurements will
be done in future in the same controlled manner, particularly around PIE load times.
Caveats - The Hidden Details
Section titled “Caveats - The Hidden Details”The performance benchmark was quite limited in terms of being an optimal case for RELR as clang is called thousands
of times in the build so on average improved load time by about 0.6-0.7ms. We can presume that using RELR on smaller
files is unlikely to regress load times. It definitely gives us confidence that it would be about the same or better in
most situations, but not noticeable or measurable in most use cases. Minimizing build times is a pretty significant
target for us, so even these small gains are appreciated.
The size savings can vary between packages and not everything can be converted into the .relr.dyn section. The current
default use of RELR is not without cost as it adds a version dependency on glibc. We will ensure we ship a sane
implementation that minimizes or removes such overhead.
It was also not straight forward to utilize RELR in Serpent. The pending upstream glibc
patch series included a patch which caused
issues when enabling RELR in Serpent OS (patch 3/5). As we utilize two toolchains, gcc/bfd and clang/lld, both
need to function independently to create outputs of a functional OS. However the part “Issue an error if there is a
DT_RELR entry without GLIBC_ABI_DT_RELR dependency nor GLIBC_PRIVATE definition.” meant that glibc would refuse to
load files linked by lld despite having the ability to load them. lld has supported RELR for some time already,
but does not create the GLIBC_ABI_DT_RELR dependency that is required by glibc. I have added my
feedback to the patch set upstream. lld now has
support for this version dependency upstream if we ever decide to use it in future.
After dropping the patch and patching bfd to no longer generate the GLIBC_ABI_DT_RELR dependency either, I was
finally able to build both glibc and LLVM with the same patches. With overcoming that hurdle, rebuilding the rest of
the repository went without a hitch, so we are now enjoying RELR in all of our builds and is enabled by default.
There is even further scope for more size savings, by switching the rela.dyn section for the rel.dyn section (this
is what is used for 32-bit builds and one of the reasons files are smaller!). lld supports switching the section type,
but I don’t believe glibc will read the output as it expects the psABI specified section (something musl can
handle though).
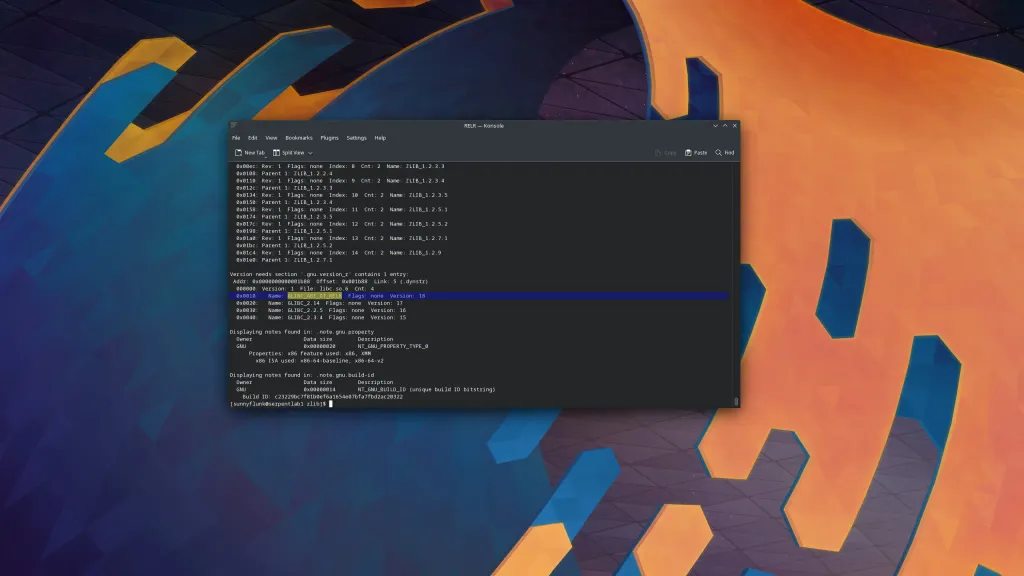
The Cost of Adding GLIBC_ABI_DT_RELR
Section titled “The Cost of Adding GLIBC_ABI_DT_RELR”A quick check of two equivalent builds (one adding the GLIBC_ABI_DT_RELR version dependency and one not), there was an
increase of 34 bytes to the file’s sections (18 bytes to .dynstr and 16 bytes to .gnu.version_r). It also means
having to validate that the GLIBC_ABI_DT_RELR version is present in the libc and that the file using RELR includes
this version dependency. This may not sound like much but it is completely unnecessary! Note that the testing provided
in this blog post is without GLIBC_ABI_DT_RELR.
Regardless of what eventuates, these negatives won’t ship in Serpent OS. This will allow for us to support files that
include the version dependency (when appimage and other distros catch up) as it will still exist in libc, but we won’t
have the version check in files, nor will glibc check that the version exists before loading for packages built by
boulder.