A post we never want to have to make!

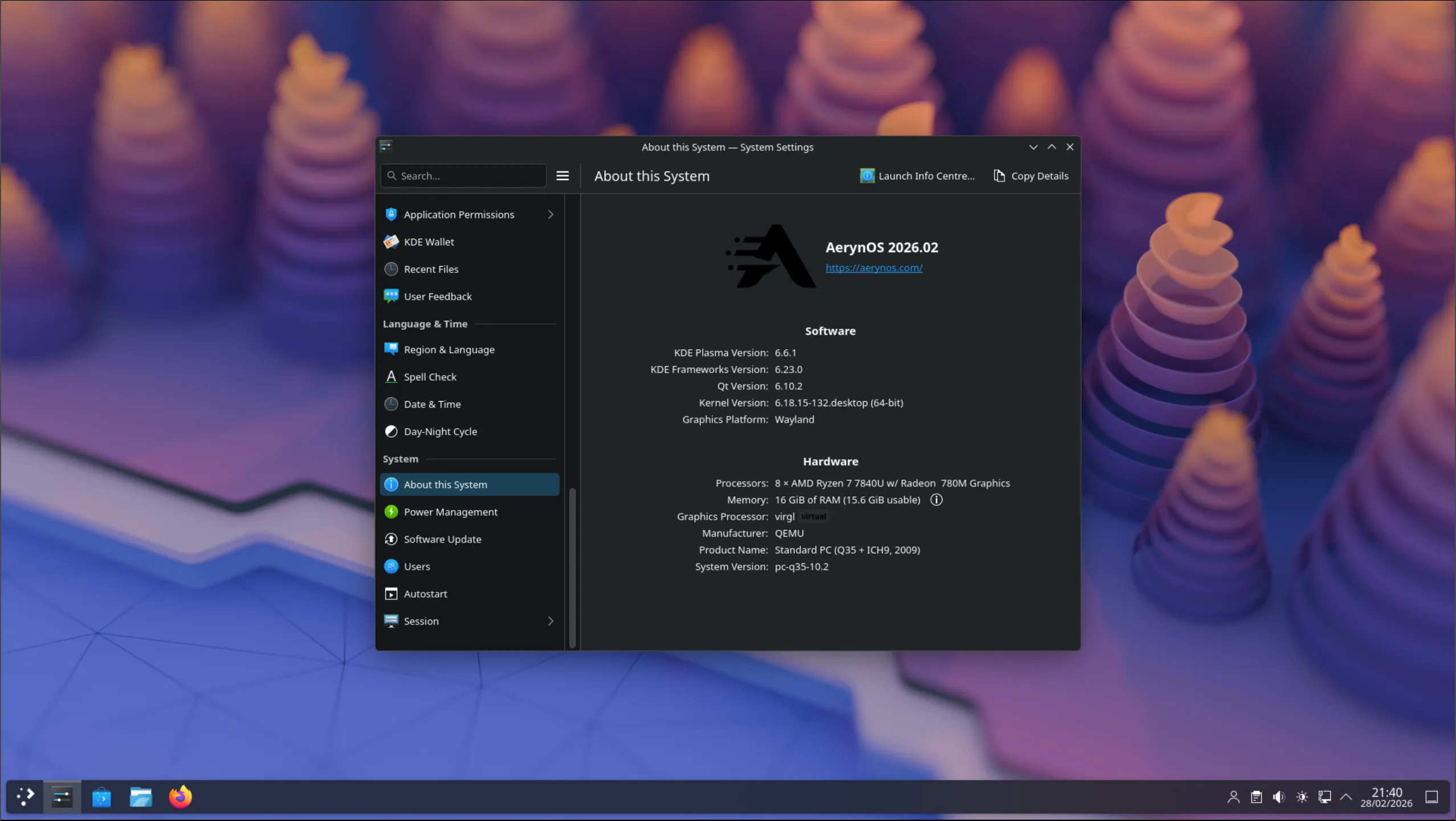
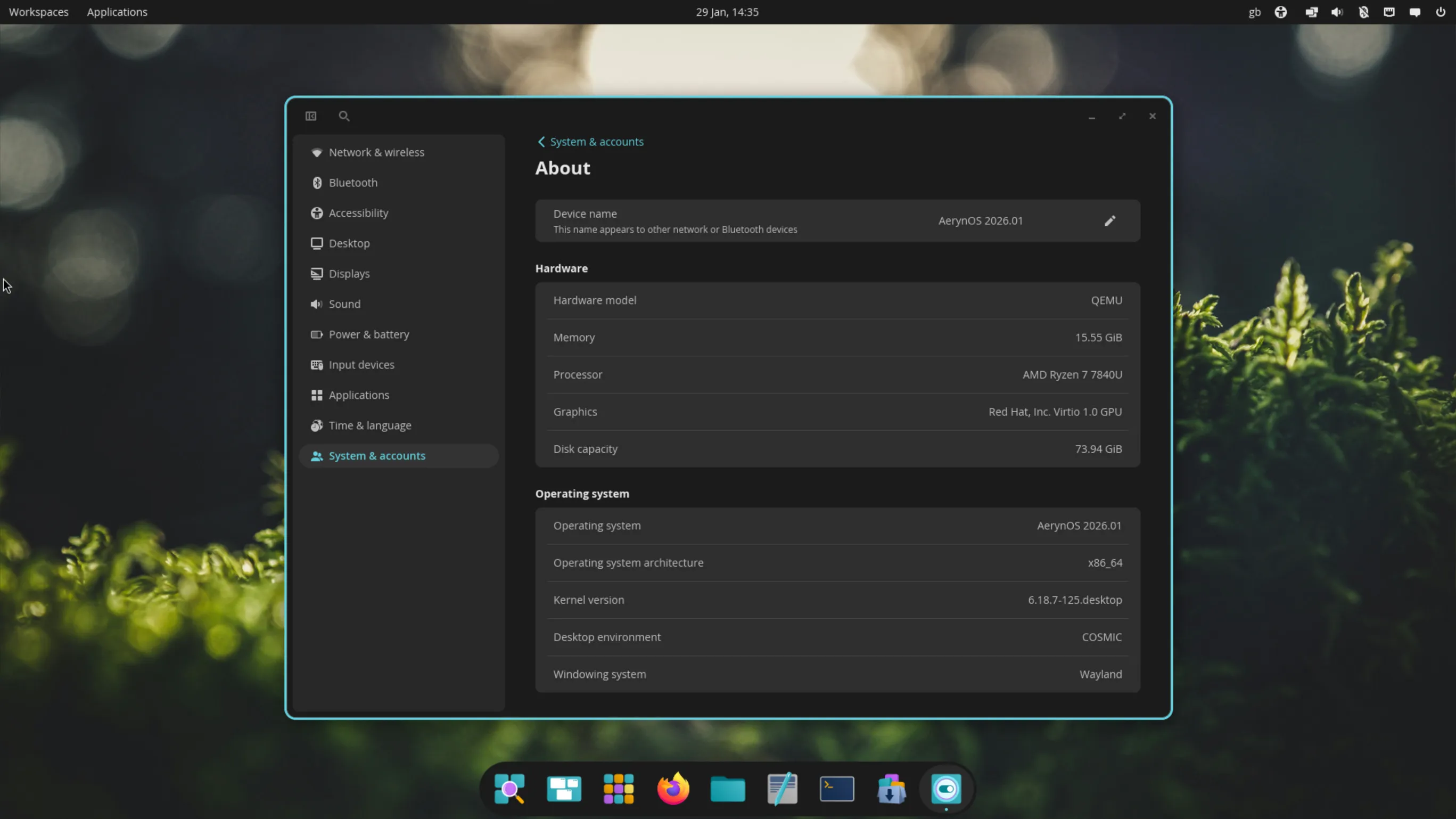
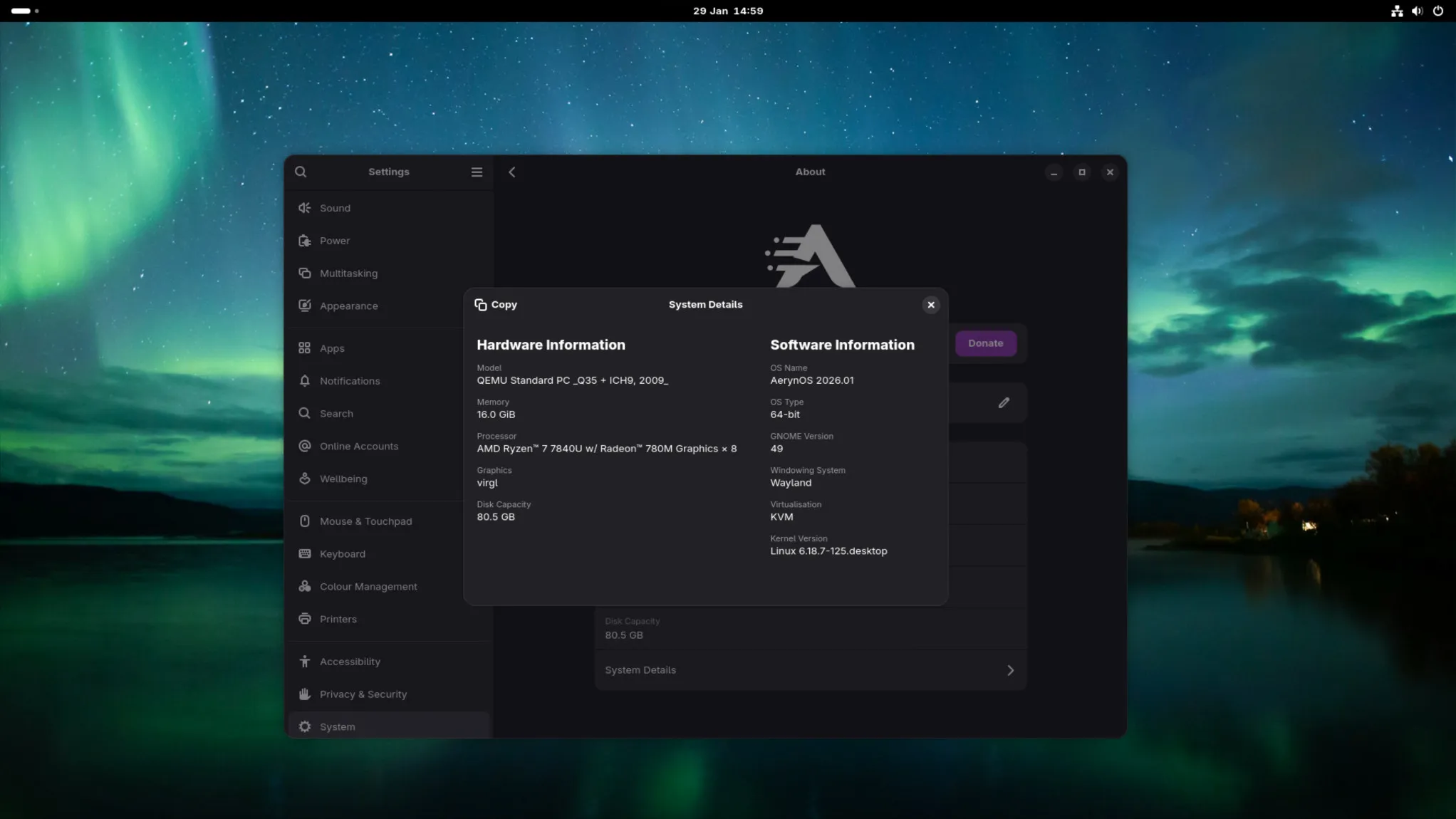
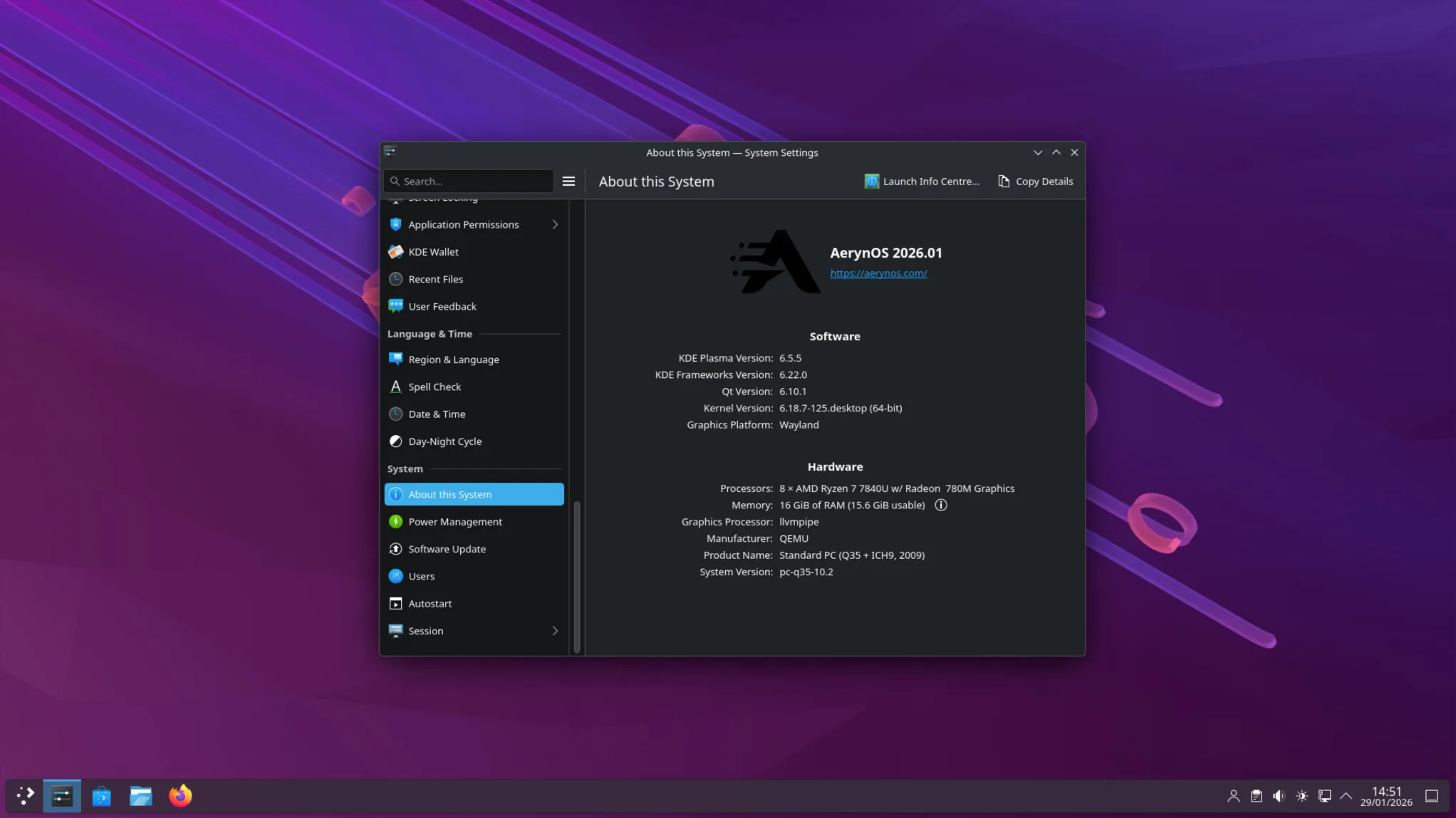
This is the post we never want to make, where we made errors with our previous ISO release and are having to take steps to fix the issue, including releasing an updated ISO.
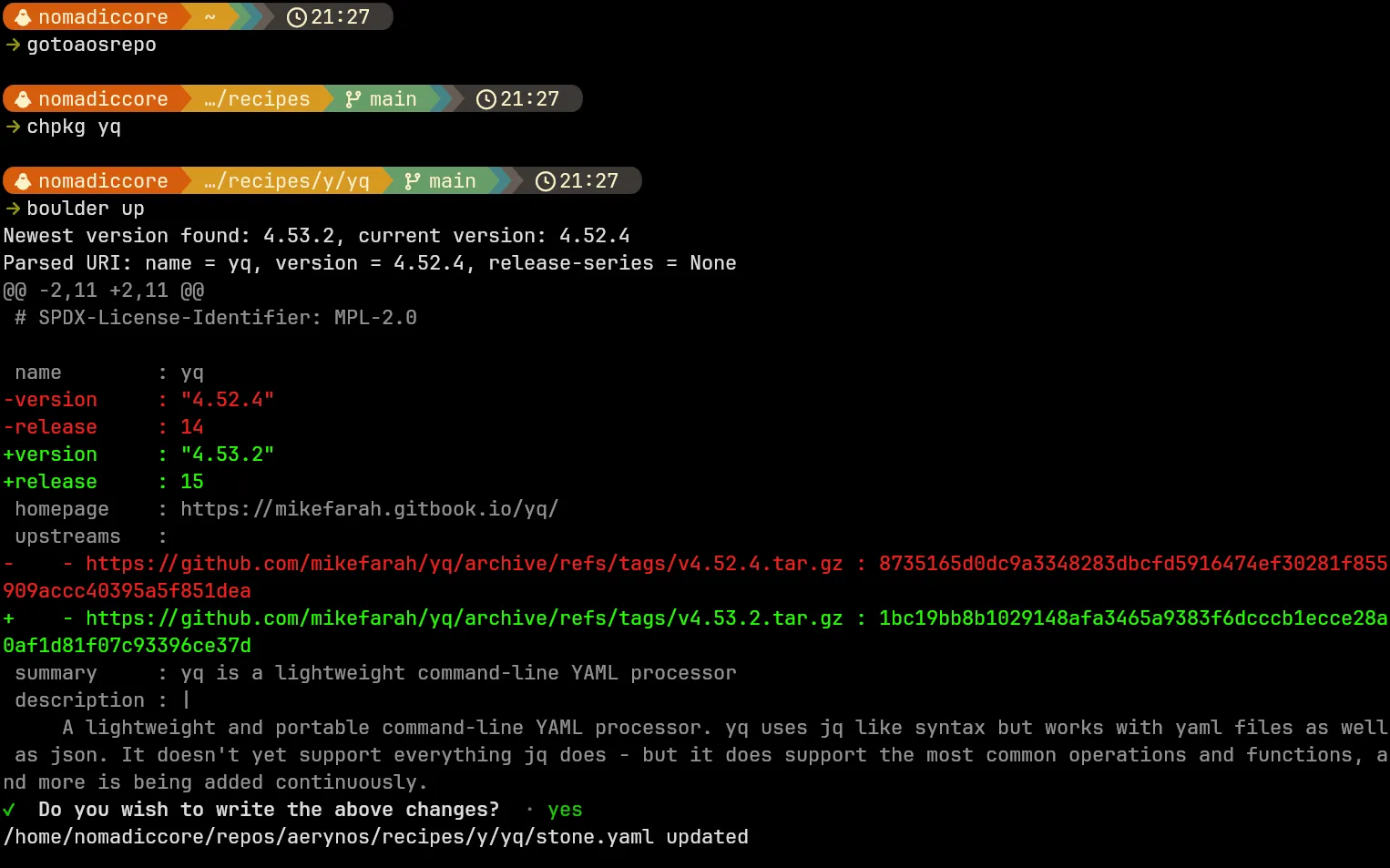
Over the course of April, the team worked on systemd-presets as a workstream we didn’t actually talk about in our April blog post. We thought that all the work had been completed in such a fashion that users wouldn’t see any discernible difference whilst allowing us to move closer to “best-practice” approaches.
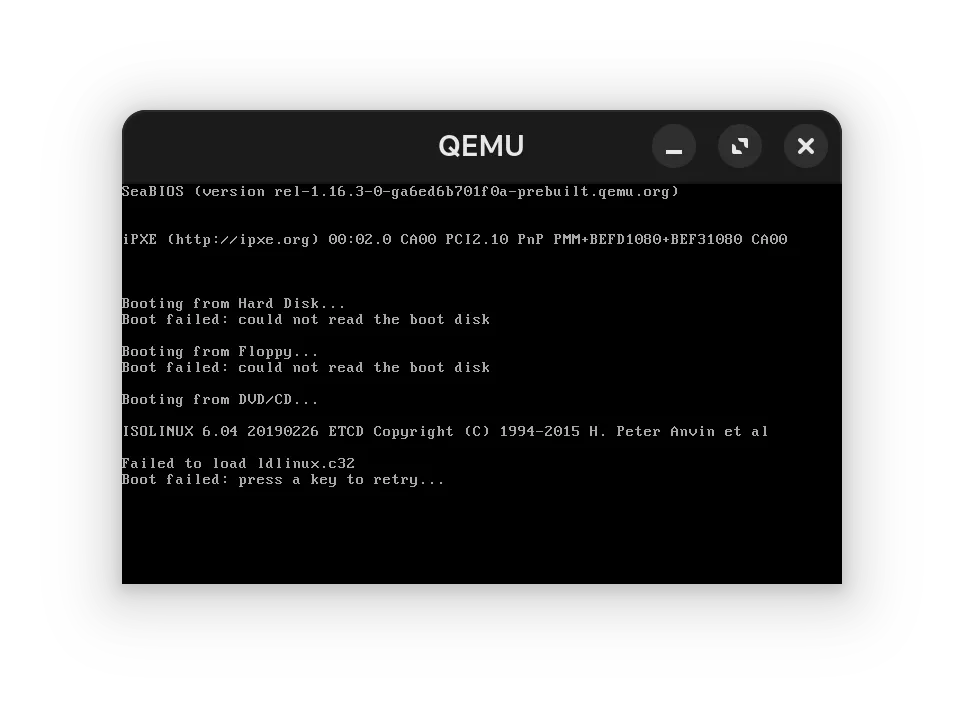
Unfortunately, due to the way systemd functions, it doesn’t natively support a global preset-all approach on first boot, one of the preset approaches we had recently adopted. In combination, our lichen installer was creating an /etc/machine-id file in new installs, which is what systemd uses to detect whether a machine is in its first boot or not.
As such, users on existing systems did not have an issue, but new installs could be broken and we did not detect this as part of our ISO testing process.
Thanks to user feedback, we were able to narrow down, identify and resolve the issue within 24 hours of the ISO release, and we had an updated ISO up for testing within our server by the end of the first day of the original release. The fix came via two commits:
- Lichen: Fix first boot
- Systemd: Preset-all user services on first-boot
Following additional testing with a wider audience on our Zulip server, we have updated the links on our download page to our new ISO so any users downloading the latest ISO won’t see these issues.
How we view the project and our roles in creating it
Section titled “How we view the project and our roles in creating it”Since taking over stewardship of AerynOS last year, we have consciously reset our own expectations of what we aim to deliver to our users / early adopters. It is a deliberate decision to keep the distro at an alpha tag, as there are certain expectations / deliverables for our core tooling we have not yet met.
We know we haven’t publicly laid out our roadmap, another deliberate decision, but this is all in service of delivering a product that early adopters (and eventually users) can rely on without having to worry about “what the hell might go wrong”.
There is an ethos within the team that we take seriously our craft, that being to create new and modern tooling that will make delivering and maintaining a Linux distribution significantly easier and more ergonomic.
In retrospect, we’re glad that in the year that we have collectively had stewardship of the project, this is the first and only time we have had to rush out a new ISO to fix an issue. We hope to not have this occur again in the future.
NVIDIA driver issues for certain GPUs
Section titled “NVIDIA driver issues for certain GPUs”In the background, we have been offering a “best effort” approach to supporting NVIDIA GPUs. This is primarily because nobody on the core team are actually using NVIDIA GPUs, and because NVIDIA’s approach to open source leaves a lot to be desired from a package- and distro-maintenance point of view.
For an alpha tag distribution that is primarily focused on dogfooding itself, NVIDIA GPU support has been — and remains — fairly low priority.
That said, Reilly identified an issue with our build ordering that caused the NVIDIA module to fail to work for GPUs that require GSP firmware. With this knowledge, we have implemented a manual fix for now. The underlying issue was already known to the team, we just hadn’t caught that it presented an issue for this particular case. Fixing that issue in our infrastructure tooling is therefore moving up on our list of priorities.
Why have monthly ISOs anyway?!
Section titled “Why have monthly ISOs anyway?!”The issue with new installs only presented because of our new ISO release. Had users installed AerynOS from any of our previous ISOs, the distribution would have installed without issue. Last year, we made a decision to move to a monthly ISO cadence as part of a wider “hearts and minds” effort, to demonstrate that AerynOS is in good hands, and that we are able to consistently deliver progress at a time when there was uncertainty of whether the project would be able to survive during Ikey’s initial (and, as it turned out, eventually permanent) absence from the project.
However, as a rolling release distro with a net-installer, it doesn’t strictly matter which ISO you boot to install AerynOS on your system (or in a VM), given that Lichen will always install from the latest unstable stream version of AerynOS. As such, we are reviewing our release cadence and will likely align releases around a couple of key factors:
- Major Linux kernel versions for new hardware support
- Updates to our installer
which will also have a benefit of reducing bandwidth consumption. This won’t however affect the frequency of our blog posts, as we have found it helpful to communicate often with those following along with the project.
We actually delivered quite a lot in the last couple of days!
Section titled “We actually delivered quite a lot in the last couple of days!”Package / stack updates for this iteration include:
Updates:
- linux stable & gaming 7.0.3
- linux LTS 6.18.26
- thunderbird 150.0.1
- asciinema 3.2.0
- enchant 2.8.16
- faugus-launcher 1.18.10
- flatpak 1.16.6
- glib2 2.88.1
- gtk-4 4.22.4
- inetutils 2.8
- libvirt 12.3.0
- rssguard 5.1.0
- wine 11.8
Fixes:
- boulder: Ensure that failing to set thread priority to SCHED_BATCH does not cause a panic w/ backtrace.
- nm-connection-editor: It’s now a separate package and can be installed without networkmanager-applet
- strawberry: Fixed not supporting common audio formats
Added:
- envision 3.2.0 (VR gaming)
- gitui: A graphical git client
- hexyl: A terminal based hex viewer with coloured output
- pkgset-oxidize: A set of pkgsets for different WM environments designed to work with the oxidize theme tool
- oxidize: A tool for atomically changing themes in supported WMs
- yt-dlp 2026.03.17
oxidize Window Manager theming
Section titled “oxidize Window Manager theming”One of our community members, Christian Bendiksen, has been working on automated theming of window managers over the last couple of months with his oxidize tool.
His work is now ready to be included in AerynOS, and can be used to automate theme setup for the four window manager options we have within AerynOS. There are many popular themes already included, and Christian has taken the initiative to play around with our new brand colour palette to make a new Aeryn theme as well!
This work builds on top of the great work Christian and a number of other dedicated contributors have been putting in to build out AerynOS’ Window Manager credentials with the inclusion of packages to bolster our offering in this area. Taking this further, Christian has also created a package set around oxidize. This package set will help simplify the process of getting set up with a great Window Manager configuration without having to go through all of the steps to get there. The next step is to take this further by utilizing our system-model approach to further develop this approach with the goal being to eventually have a simple preconfigured Window Manager option available out of the box.
Of course, for those wishing to configure their Window Manager experience from scratch, this option is of course available to you as well.
ISO refresh
Section titled “ISO refresh”With this blog post, we already have a new 2026.05.2 ISO available on our download page.
It incorporates all the changes and package updates highlighted above and as usual, serves as a vessel for you to use lichen to install AerynOS onto your system or into a virtual machine.
Next Steps
Section titled “Next Steps”The primary focus on the development side is (still) to attempt to get the Versioned Repos, phase2 feature over the finish line as soon as feasible.
Frankly, we have been so focused on getting the Versioned Repos, phase2 feature right, that we’ve scarcely had the mental bandwidth to focus on anything else from the perspective of our larger development arc.
That said — and assuming we succeed in landing the Versioned Repos, phase2 feature soon — we will then spend some time on sketching out the details of the upcoming avenues of development that will open up as a result.
In parallel to that, we hope to spend some time getting our systemd-preset story straight from a packaging perspective, which will give us the ability to enable services as a packaging operation. This will be especially useful when leveraged via our declarative system-model capabilities.
Supporting the project
Section titled “Supporting the project”Outside of financial donations through Stripe and Ko-fi mentioned above, we are always looking for people to get involved with development and packaging efforts and welcome anyone curious about AerynOS to join us in our Zulip server!
If any hardware vendors are interested in sponsoring the project either financially or through hardware sponsorship, this would be warmly received.
If you wish to discuss other sponsorship opportunities, such as hosting or hardware sponsorship, please reach out to us at contact@aerynos.com.
Thank You!
Section titled “Thank You!”We are very grateful for your support, be it financial or via project contributions in the form of carefully written bug reports, code contributions, design contributions, documentation updates, general feedback, package updates and overall enthusiasm around the project.
We hope that you will continue showing enthusiasm for our project, and that you will want to get involved in whichever way, shape, or form works for you!