It All Depends
It all depends.. it really does. On shared libraries.. interpreters.. pkg-config providers
and packages. It’s the same story for all “package managers”, how do we ensure that the
installed software has everything it needs at runtime?
Our merry crew has been involved in designing and building Linux distributions for a very, very long time, so we didn’t want to simply repeat history.
Thanks to many improvements across our codebase, including moss-deps, we automatically analyse
the assets in a package (rapidly too) to determine any dependencies we can add without requiring
the maintainer to list them. This is similar in nature to RPM’s behaviour.
As such we encode dependencies into our (endian-aware, binary) format which is then stored in the local installation database. Global providers are keyed for quick access, and the vast majority of packages will not explicitly depend on another package’s name, rather, they’ll depend on a capability or provider. For subpackage dependencies that usually depend on “NEVRA” equality (i.e. matching against a name with a minimum version, release, matching epoch and architecture), we’ll introduce a lockstep dependency that can only be resolved from its origin source (repo).
Lastly, we’ll always ensure there is no possibility for “partial update” woes. With these
considerations, we have no need to support >= style dependencies, and instead rely on
strict design goals and maintainer responsibility.
First and foremost!
Section titled “First and foremost!”The rapid move we’re enjoying from concept, to prototype, and soon to be fully fledged Linux distribution, is only possible with the amazing community support. The last few months have seen us pull off some amazing feats, and we’re now executing on our first public milestones. With your help, more and more hours can be spent getting us ready for release, and would probably help to insulate my shed office! (Spoiler: its plastic and electric heaters are expensive =))
The Milestones
Section titled “The Milestones”We have created our initial milestones that our quite literally our escape trajectory from bootstrap to distro. We’re considerably closer now, hence this open announcement.
v0.0: Container (systemd-nspawn)
Section titled “v0.0: Container (systemd-nspawn)”Our first release medium will be a systemd-nspawn compatible container image. Our primary
driver for this is to allow us to add encapsulation for our build tool, boulder, permitting
us to create distributable builder images to seed our infrastructure and first public binary
repository.
v0.1: Bootable “image”
Section titled “v0.1: Bootable “image””Once our build infra is up and running (honestly a lot of work has been completed for this in
advance) we’ll work towards our first 0.1 image. This will initially target VM usage, with
a basic console environment and tooling (moss, boulder, etc).
And then..
Section titled “And then..”We have a clear linear path ahead of us, with each stage unlocking the next. During the development
of v0.0 and v0.1 we’ll establish our build and test infrastructure, and begin hosting our
package sources and binaries. At this point we can enter a rapid development cycle with
incremental, and considerable improvements. Such as a usable desktop experience and installer.. :)
Recent changes
Section titled “Recent changes”I haven’t blogged in quite a while, as I’ve been deep in the trenches working on our core features. As we’ve expressed before, we tend to work on the more complex systems first and then glue them together after to form a cohesive hole. The last few days have involved plenty of glue, and we now have distinct package management features.
Refactor
Section titled “Refactor”- Replaced defunct InstallDB with reusable MetaDB for local installation of archives as well as forming the backbone of repository support.
- Added
ActivePackagesPluginto identify installed packages - Swapped non cryptographic hash usage with
xxhash
Dependencies
Section titled “Dependencies”- Introduced new Transaction type to utilise a directed acyclical graph for dependency solving.
- Reworked moss-deps into plugins + registry core for all resolution operations.
- Locally provided
.stonefiles handled byCobblePluginto ensure we depsolve from this set too. - New Transaction set management for identifying state changes and ensuring full resolution of target system state.
- Shared library and interpreter (DT_INTERP) dependencies and producers automatically encoded into packages and resolved by depsolver.
Package Installation
Section titled “Package Installation”We handle locally provided .stone packages passed to the install command identically to
those found in a repository. This eliminates a lot of special casing for local archives and
allows us to find dependencies within the provided set, before looking to the system and the
repositories.

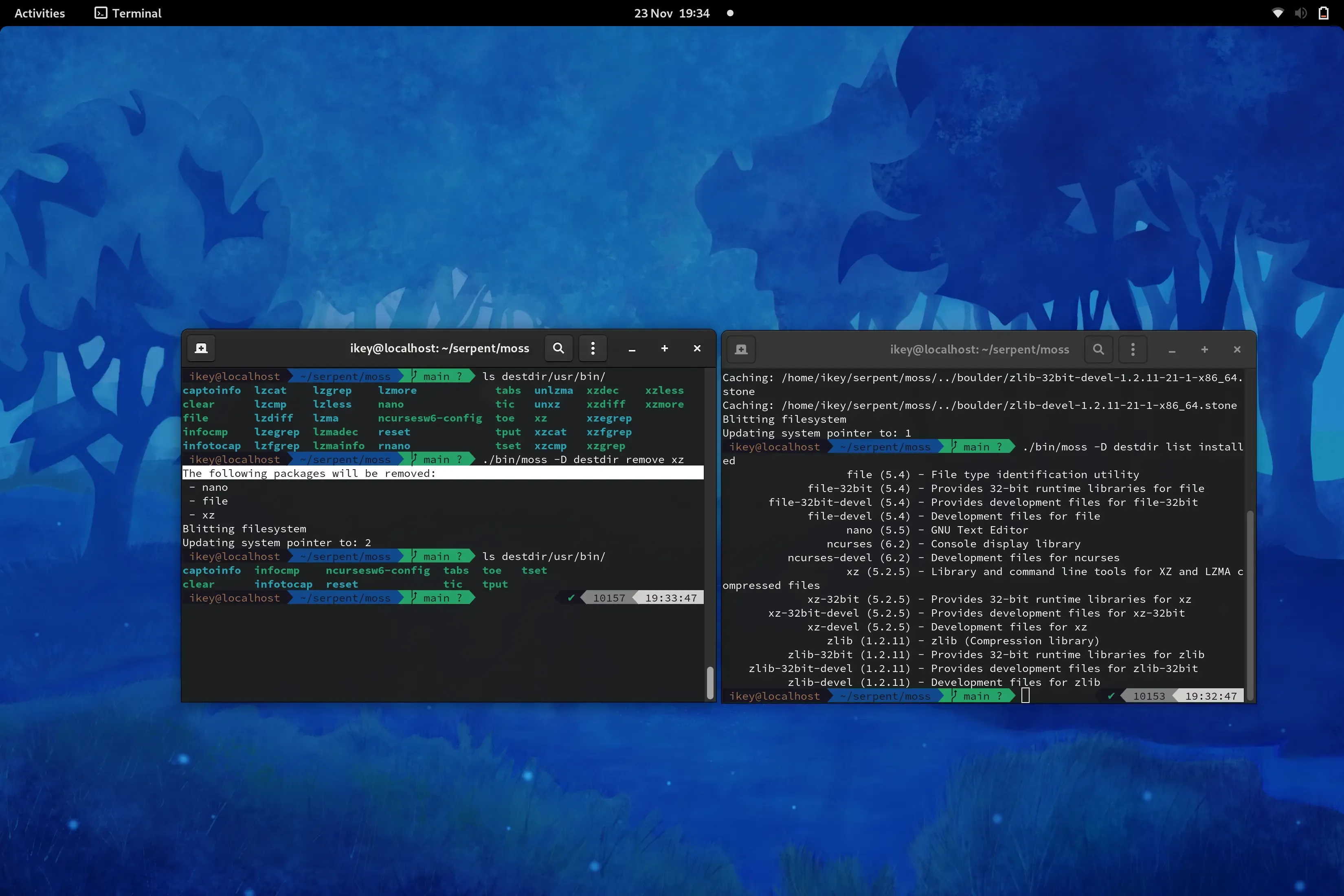
Dependency resolution is performed now for our package installation and is validated at multiple points, allowing a package like nano to depend on compact automatic dependencies:
Dependency(DependencyType.SharedLibraryName, "libc.so.6(x86_64)");Note our format and database are binary and endian aware. The dependency type only requires 1 byte of storage and no string comparisons.
List packages
Section titled “List packages”Thanks to the huge refactor, we can now trivially access the installed packages as a list.
This code will be reused for a list available command in future.
Example list installed output:
file (5.4) - File type identification utility file-32bit (5.4) - Provides 32-bit runtime libraries for file file-32bit-devel (5.4) - Provides development files for file-32bit file-devel (5.4) - Development files for file nano (5.5) - GNU Text Editor
Inspect archives
Section titled “Inspect archives”For debugging and development purposes, we’ve moved our old “info” command to a new
“inspect” command to work directly on local .stone files. This displays extended
information on the various payloads and their compression stats.
For general users - the new info command displays basic metadata and package
dependencies.

Package Removal
Section titled “Package Removal”Upon generating a new system state, “removed” packages are simply no longer installed. As such no live mutation is performed. As of today we can now request the removal of packages from the current state, which generates a new filtered state. Additionally we remove all reverse dependencies, direct and transitive. This is accomplished by utilising a transposed copy of the directed acyclical graph, identifying the relevant subgraph and occluding the set from the newly generated state.

Lastly
Section titled “Lastly”The past few weeks have been especially enjoyable. I’ve truly had a fantastic time working on the project and cannot wait for the team and I to start offering our first downloads, and iterate as a truly new Linux distribution that borrows some ideas from a lot of great places, and fuses them into something awesome.
Keep toasty - this train isn’t slowing down.